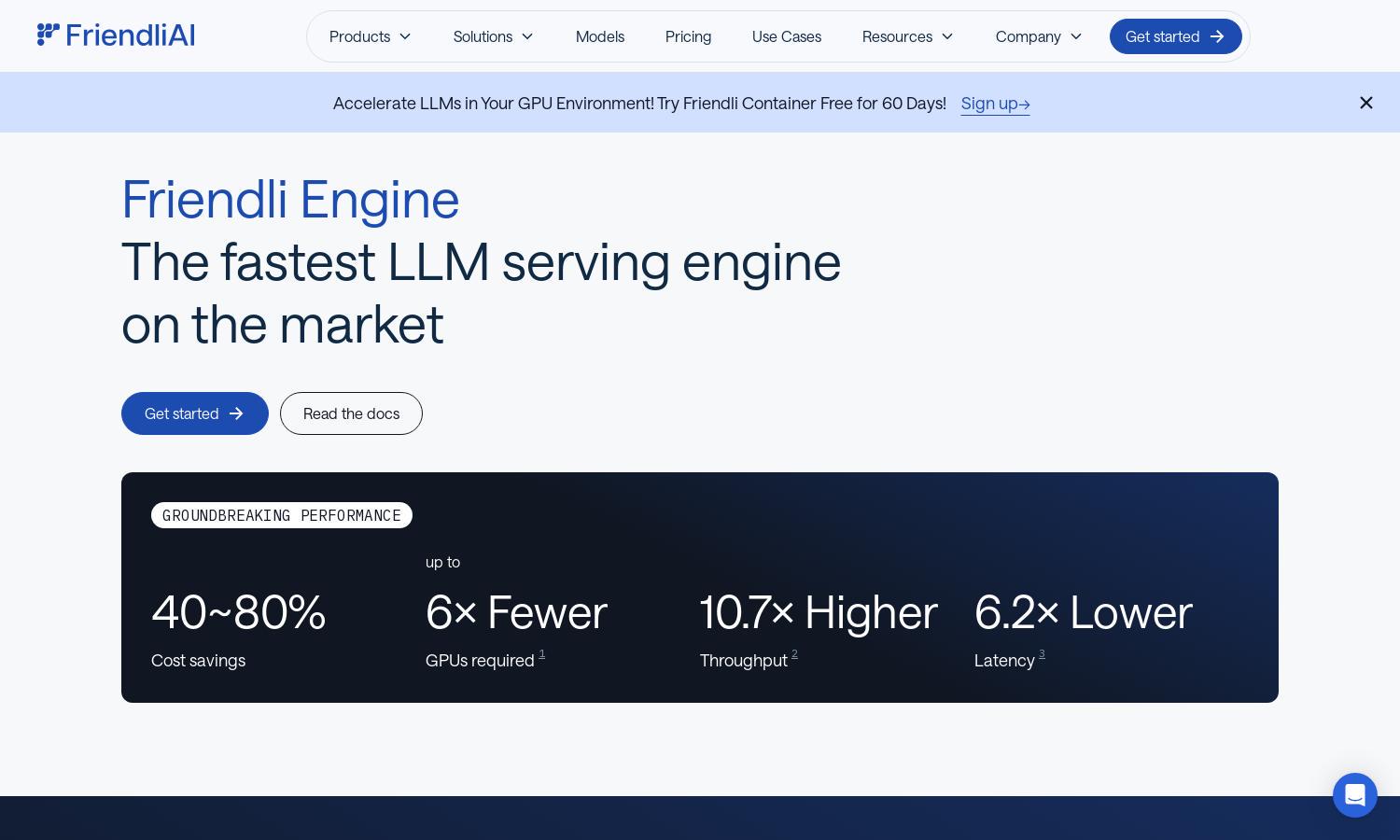
Friendli Engine
About Friendli Engine
Friendli Engine is designed for businesses utilizing generative AI, enhancing LLM inference efficiency. By integrating advanced features like iteration batching and speculative decoding, it supports multiple LLMs on fewer GPUs, significantly reducing costs and response times. Ideal for developers and organizations seeking optimized AI solutions.
Friendli Engine offers flexible pricing plans based on usage, ensuring cost-effectiveness. Users can choose from dedicated endpoints, container options, or serverless APIs, averaging significant cost savings. Upgrading allows access to more advanced features and optimization tools, enhancing the overall efficiency of AI model deployment.
Friendli Engine boasts a user-friendly design, providing seamless navigation for testing and deploying AI models. The layout emphasizes easy access to features like benchmarking and performance metrics, with intuitive controls ensuring a smooth user journey. This design enables developers to maximize their productivity with generative AI.
How Friendli Engine works
To start with Friendli Engine, users sign up and choose their desired model deployment method. They can opt for dedicated endpoints, containers, or serverless options based on their needs. The intuitive dashboard simplifies navigation, allowing users to configure LLM settings, monitor performance metrics, and access comprehensive benchmarking tools to optimize their generative AI tasks.
Key Features for Friendli Engine
Iteration Batching Technology
Friendli Engine features a unique iteration batching technology that enables high throughput for LLM inference. This innovative approach drastically improves efficiency by accommodating multiple requests simultaneously, significantly reducing inference times while maintaining performance, making it a vital tool for developers and businesses utilizing AI technology.
Multi-LoRA Support
The Friendli Engine supports multiple LoRA models on a single GPU, allowing for efficient LLM customization and deployment. This key feature streamlines generative AI processes, making it easier for users to manage diverse models, enabling users to achieve their AI objectives without the need for extensive GPU resources.
Speculative Decoding
Friendli Engine incorporates speculative decoding, a cutting-edge optimization technique that enhances LLM inference speeds. By predicting future tokens, it enables quicker generation times while ensuring accuracy, setting Friendli Engine apart as a highly effective solution for businesses needing rapid AI model responses without compromising quality.
You may also like:







