ImageBind by Meta AI
About ImageBind by Meta AI
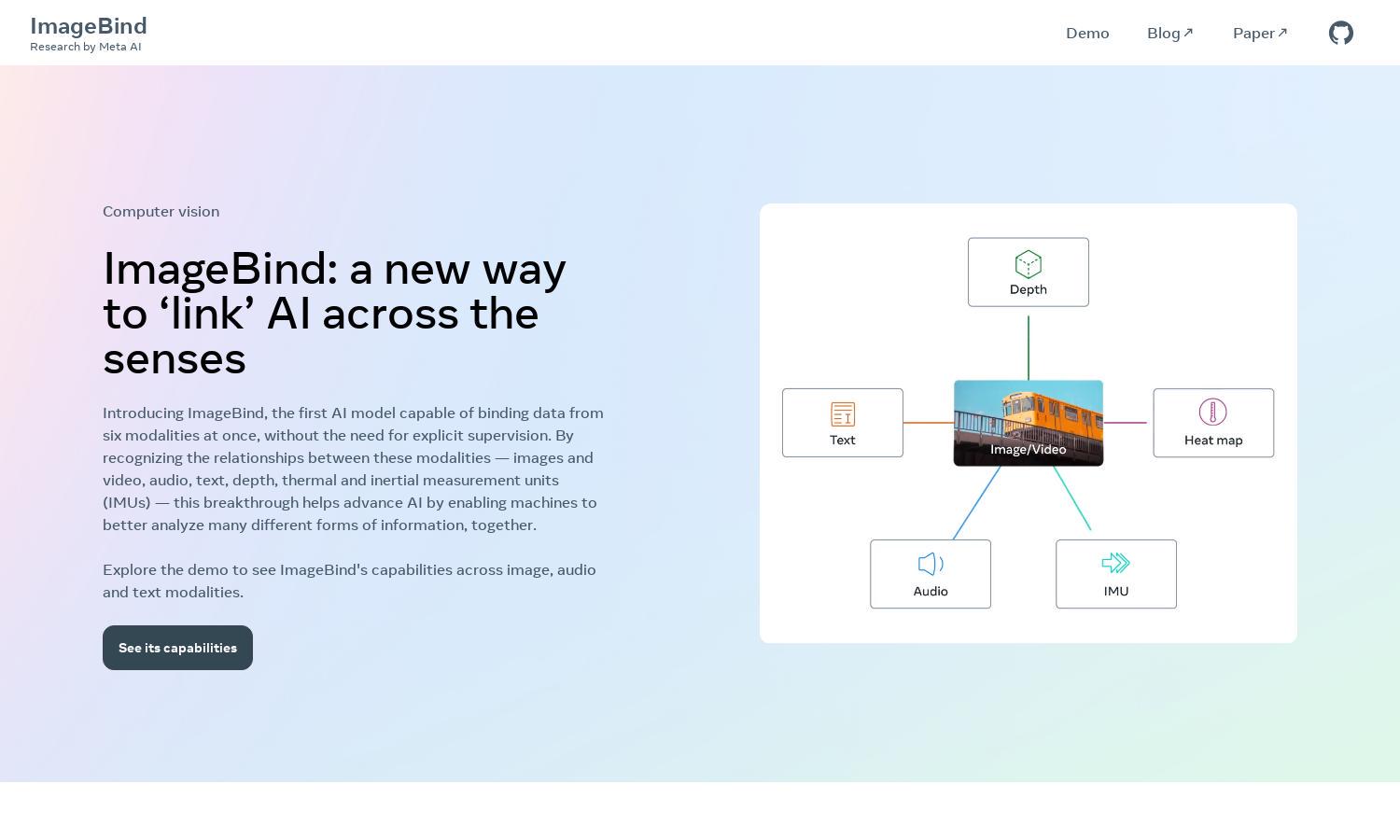
ImageBind, developed by Meta AI, transforms AI by binding multiple modalities like images, audio, and text into a coherent embedding space. Its innovative approach allows seamless integration and analysis of diverse datasets, empowering users to perform advanced recognition tasks and enhancing machine understanding, making it indispensable for developers and researchers.
ImageBind offers open-source access with no subscription fees. Users can freely explore its capabilities. Upgrading to premium resources provides enhanced support and future updates, maximizing the potential of the model. Discover more about ImageBind's expansive features without worrying about high costs, enabling greater AI exploration.
ImageBind features a user-friendly interface designed for seamless interaction. Users navigate through the demo easily, accessing functionalities like multimodal analysis and comparisons. This intuitive layout enhances overall user experience, making tasks simpler and more efficient while showcasing the multi-sensory capabilities of ImageBind in an engaging manner.
How ImageBind by Meta AI works
Users begin by accessing ImageBind through its web app, where they can easily explore the demo showcasing its capabilities across different modalities. After navigating the interface, users can test various inputs—images, audio, and text—and observe the model's ability to bind these modalities simultaneously, facilitating advanced AI tasks like cross-modal searches and recognition.
Key Features for ImageBind by Meta AI
Multimodal Embedding
ImageBind's unique multimodal embedding connects images, audio, and text, enhancing AI's analysis capabilities. This innovative feature allows users to perform advanced recognition tasks and cross-modal searches seamlessly, like never before. By integrating diverse inputs, ImageBind simplifies and enriches the data analysis process for researchers and developers.
Zero-shot Recognition
ImageBind excels in zero-shot recognition, outperforming specialized models trained on specific modalities. This groundbreaking functionality enables users to achieve superior recognition results across various data types without retraining, significantly enhancing the efficiency and flexibility of AI applications, making ImageBind a powerful tool for cutting-edge projects.
Cross-modal Generation
Cross-modal generation in ImageBind allows users to create outputs across different modalities based on a single input type. This unique feature enhances creativity and experimentation in AI projects, enabling developers to generate compelling multimedia content effortlessly, showcasing the transformative power of ImageBind in multimedia applications.