Tuning Engines
Tuning Engines is a unified, governed orchestrator that secures, optimizes, and audits every AI interaction through a single API with transparent.
Visit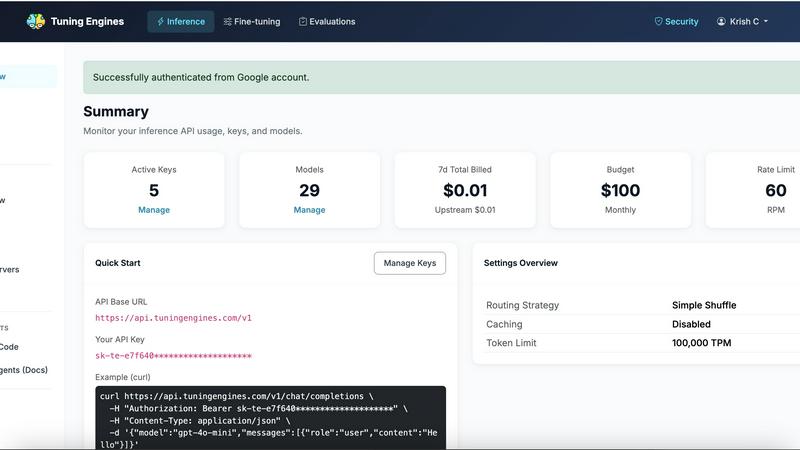
About Tuning Engines
Tuning Engines, a product by CerebrixOS, is a unified AI control and governance layer designed for teams building production intelligence across models, agents, tools, and fine-tuned systems. It functions as a comprehensive platform that brings together the full AI lifecycle into one governed environment, covering inference, model routing, fallback policies, fine-tuning jobs, datasets, evaluations, model imports and exports, custom models, agents, MCP servers, reusable skills, guardrails, policy-as-code, data capture, runtime traces, usage analytics, API keys, billing, team roles, and integrations. The platform is built for organizations that need to move beyond isolated AI experiments into a secure, observable, cost-aware, and extensible AI operating layer where models can be trained, evaluated, routed, governed, and used by agents and tools at scale. Developers benefit from OpenAI-compatible APIs, Anthropic-compatible routes, CLI workflows, MCP access, coding-agent integrations, and resource catalogs for models, agents, tools, and skills. Administrators gain production controls including role-based access, per-key budgets, rate limits, routing profiles, fallback rules, guardrails, policy-as-code, credential sources, auditability, usage traces, billing controls, tenant isolation, and team management. A key differentiator is that infrastructure costs are passed through at-cost with zero markup, meaning organizations only pay for support and platform upkeep. The platform is backed by Google Cloud for Startups, NVIDIA Inception, Rogers Cybercatalyst, ElevenLabs Grants, AWS Activate, and BDC Capital.
Features of Tuning Engines
Unified Inference
One OpenAI-compatible endpoint provides access to open models, commercial frontier models, and your own tuned models through a single API. Developers can keep their existing SDK and simply swap one base URL to call any model with centralized policy, full auditability, and token controls applied to every request. This eliminates the need for code rewrites or learning new client libraries.
Model Tuning
Organizations can adapt open models to their specific data, workflows, and production goals using supervised fine-tuning and LoRA adapters. The platform handles all GPU infrastructure management, allowing teams to focus on improving model quality rather than managing hardware. Evaluation gates ensure that quality improvements are measurable and aligned with business requirements.
Policy and Governance
Centralized guardrails, access controls, and full request traceability are applied across every model interaction. Administrators can implement role-based access, per-key budgets, rate limits, routing profiles, fallback rules, and policy-as-code through AGT YAML policies. This ensures that every AI interaction is governed, auditable, and compliant with organizational standards.
Token Economics
Cost ceilings, quotas, routing, and fallback mechanisms keep spend and rate limits predictable across all AI workloads. The platform provides detailed usage analytics, billing controls, and tenant isolation so organizations can manage costs at scale. Infrastructure costs are passed through at-cost with zero markup, meaning users only pay for support and platform upkeep.
Use Cases of Tuning Engines
Code Assistance
IDE copilots, code generation, refactoring, and debugging agents can be built and governed through the platform. Teams can connect tools like Claude Code, OpenCode, Aider, Cline, Roo, Continue.dev, Cursor, VS Code, and Windsurf through a single governed platform, ensuring consistent policy enforcement and auditability across all coding workflows.
Conversational AI
Customer support bots, internal helpdesks, and multilingual chat applications can be deployed with centralized policy control and cost management. The unified inference endpoint allows teams to switch between models for different conversation types, while guardrails ensure appropriate responses and budget controls prevent unexpected costs.
Agentic Systems
Multi-step reasoning, planning, and tool-using execution pipelines can be built and governed within the platform. Agents can access models, MCP servers, reusable skills, and tools through resource catalogs, with full traceability and policy enforcement across every step of the reasoning process.
Enterprise RAG
Secure, scalable retrieval over knowledge bases and private documents is supported through the platform's evaluation and governance capabilities. Teams can fine-tune models on enterprise data, implement guardrails for sensitive information, and monitor usage analytics to ensure compliance and cost efficiency.
Frequently Asked Questions
What models are available through Tuning Engines?
The platform provides instant access to popular open weight models including Llama 3.3 70B, Llama 3.1 8B, DeepSeek V3, DeepSeek R1, Qwen 2.5 72B, Qwen 2.5 Coder 32B, Mistral Small 3, Mixtral 8x7B, Gemma 2 27B, Llama 3.2 Vision, Whisper Large v3, and Embeddings from the BGE/E5 family. Additionally, commercial frontier models and any models you fine-tune with the platform are accessible through the same unified endpoint.
How does the unified API work?
The platform provides a drop-in OpenAI-compatible endpoint that works with your existing SDK. You simply change your base URL to https://api.tuningengines.com/v1 and use your API key. You can then call any open, commercial, or tuned model with centralized policy, full auditability, and token controls applied to every request without any code rewrites.
What governance controls are available for administrators?
Administrators get role-based access control, per-key budgets, rate limits, routing profiles, fallback rules, guardrails, policy-as-code through AGT YAML policies, credential sources, auditability, usage traces, billing controls, tenant isolation, and team management. These controls ensure production-ready governance across all AI interactions.
How does pricing work for infrastructure costs?
Infrastructure costs are passed through at-cost with zero markup. Organizations only pay for support and platform upkeep. This means there are no hidden margins on compute, storage, or model inference costs, making the platform cost-transparent and predictable for teams scaling their AI operations.
Pricing of Tuning Engines
The platform operates on a cost-transparent model where infrastructure costs are passed through at-cost with zero markup. Organizations pay only for support and platform upkeep. Specific pricing plans, tiers, or costs are not detailed in the available context. For detailed pricing information, users are directed to contact the Tuning Engines team through their website.
Similar to Tuning Engines
Distro is an AI Distribution Operator that helps B2B teams publish content, find buyer conversations, engage prospects, and turn social intent into pi
Polymarket Trading Bot For Crypto
Skygen AI automates your tasks with intelligent agents that streamline workflows, enhance productivity, and deliver actionable results.
HyperLake provides a sovereign AI infrastructure with zero compute markup, enabling seamless deployment and governance for autonomous agents in your.
Minded empowers teams to effortlessly train AI agents that handle tasks efficiently, streamlining operations and enhancing customer service.
YCaaS provides comprehensive AI agents that seamlessly manage all roles and tasks from start to finish, enhancing operational efficiency.
xyOps is a powerful workflow automation platform that simplifies job scheduling, monitoring, and alerting for any infrastructure scale.
Nudgen is an AI-powered retention email platform that automates personalized, on-brand campaigns to boost customer lifetime value for shop owners and.