Agenta vs Fallom
Side-by-side comparison to help you choose the right product.
Agenta is an open-source LLMOps platform that centralizes prompt management and evaluation for reliable AI development.
Last updated: March 1, 2026
Fallom provides comprehensive AI observability for real-time tracking, debugging, and cost analysis of LLM agents.
Last updated: February 28, 2026
Visual Comparison
Agenta
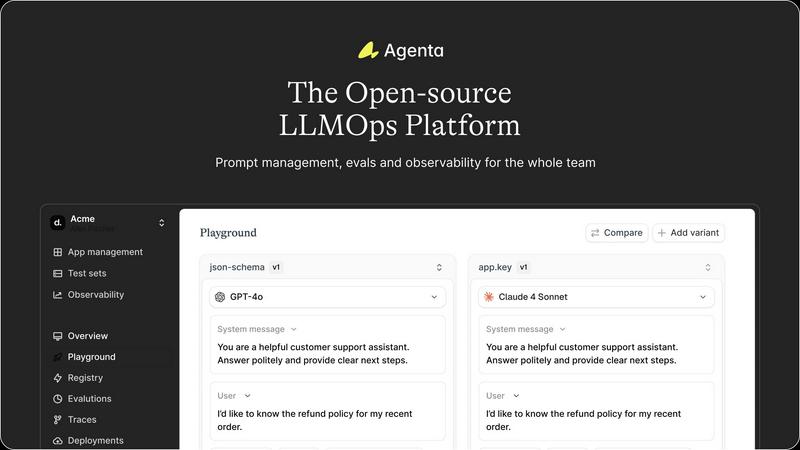
Fallom
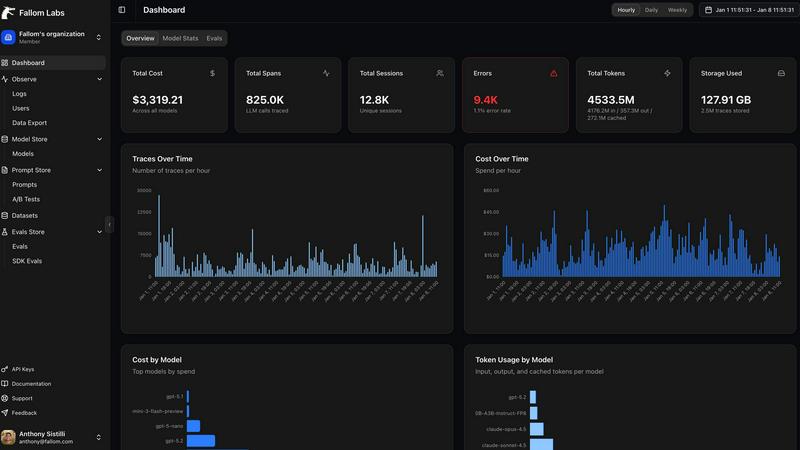
Feature Comparison
Agenta
Centralized Prompt Management
Agenta's centralized prompt management feature allows teams to keep all prompts, evaluations, and traces in one unified platform, eliminating the chaos of scattered tools. This ensures that everyone involved has access to the latest versions of prompts and can collaborate effectively without losing critical information.
Automated Evaluation Processes
With Agenta, teams can create systematic evaluation processes that automate the testing and validation of every change made to prompts and models. This feature minimizes guesswork and allows for more reliable assessments of model performance through integrated evaluators that can be customized as needed.
Comprehensive Observability Tools
Agenta provides robust observability tools that allow teams to trace every request and pinpoint exact failure points in their AI systems. This feature facilitates effective debugging and helps gather vital user feedback, which can be annotated and transformed into actionable test cases with a single click.
Unified Collaboration Interface
The platform includes a user-friendly interface that empowers domain experts, product managers, and developers to work together within a single workflow. This feature simplifies the process of experimenting, comparing, versioning, and debugging prompts, making it easier for all team members to contribute without needing deep technical expertise.
About Fallom
End-to-End LLM Tracing
Fallom provides comprehensive, OpenTelemetry-native tracing for every LLM call and agentic workflow. Each trace captures a complete picture of the interaction, including the exact prompt sent, the model's raw output, token usage (input and output), precise latency metrics, and the calculated per-call cost. For AI agents, it extends this visibility to every tool call, logging function arguments and results, creating a detailed execution graph that is indispensable for debugging complex, stateful operations and understanding the root cause of failures or unexpected behavior.
Granular Cost Attribution & Analytics
The platform offers unparalleled transparency into AI expenditure by breaking down costs across multiple dimensions. Teams can track and attribute spend per specific LLM model (e.g., GPT-4o vs. Claude-3.5), per internal team or project, and per end-user or customer. This feature enables precise budgeting, internal chargeback mechanisms, and data-driven decisions on model selection. Interactive dashboards visualize cost distribution, helping identify optimization opportunities and justify AI investments with clear, auditable financial data.
Enterprise Compliance & Audit Trails
Fallom is architected to meet the rigorous demands of regulated industries. It maintains immutable, complete audit trails of all LLM interactions, which is a foundational requirement for frameworks like the EU AI Act and GDPR. Key capabilities include detailed input/output logging, model version lineage to track which model generated a specific output, and user consent tracking. A configurable "Privacy Mode" allows organizations to redact sensitive content or log only metadata, ensuring observability without compromising data privacy or confidentiality.
Advanced Performance & Testing Tools
Beyond basic monitoring, Fallom includes a suite of tools for performance optimization and quality assurance. The Timing Waterfall visualization breaks down latency within multi-step agent calls, pinpointing bottlenecks in LLM responses or tool execution. Integrated evaluation frameworks allow teams to run automated tests on LLM outputs for metrics like accuracy, relevance, and hallucination rates. Coupled with model A/B testing and a version-controlled Prompt Store, these features enable systematic performance comparison, safe rollouts of new models or prompts, and proactive regression detection.
Use Cases
Agenta
Collaborative Development of LLM Applications
Agenta is ideal for teams looking to collaboratively develop LLM applications. By providing a centralized platform, it allows developers and subject matter experts to work together on prompt engineering and model evaluation, fostering innovation and efficiency.
Streamlined Debugging and Performance Monitoring
AI teams can leverage Agenta to streamline their debugging processes. The observability tools allow them to identify and address issues quickly, while the automated evaluation processes ensure continuous performance monitoring, helping to maintain high-quality standards in production.
Agile Iteration and Experimentation
Agenta supports agile methodologies by enabling rapid iteration of prompts and models. Teams can experiment with various approaches, track their results, and validate changes effectively, ensuring that their LLM applications remain competitive and responsive to user needs.
Integration with Existing Workflows
Agenta's ability to integrate seamlessly with popular frameworks and models like LangChain, LlamaIndex, and OpenAI makes it a versatile choice for teams. This feature enables organizations to leverage their existing technology stack while adopting best practices in LLMOps.
Fallom
Debugging and Optimizing AI Agents
Development and operations teams use Fallom to debug intricate AI agent workflows that involve sequential LLM calls and external tool usage (e.g., database queries, API calls). By examining the detailed trace with tool call visibility and timing waterfalls, engineers can quickly identify which step in a chain failed, why a particular tool was called with unexpected arguments, or where latency is accumulating, drastically reducing mean time to resolution (MTTR) and improving agent reliability.
Ensuring Regulatory Compliance and Audit Readiness
Legal, compliance, and security teams in finance, healthcare, or enterprise software leverage Fallom to demonstrate adherence to AI regulations. The platform's comprehensive audit trails, consent tracking, and model versioning provide the necessary documentation to prove how AI models are used, what data they processed, and that appropriate governance controls are in place. This is critical for passing internal and external audits and mitigating regulatory risk.
Managing and Controlling AI Operational Costs
Engineering leads and finance departments utilize Fallom's cost attribution dashboards to gain full visibility into AI spending. By analyzing costs per model, team, or feature, they can identify inefficient patterns, optimize prompts, right-size model selection, and implement chargeback or showback models. This transforms AI costs from an opaque overhead into a manageable and accountable operational expense, ensuring sustainable scaling.
Monitoring Production Health and User Experience
Site reliability engineers (SREs) and product managers rely on Fallom's real-time dashboard to monitor the health and performance of AI features in production. They can spot anomalies in latency, error rates, or token usage as they happen, set alerts for thresholds, and understand usage patterns by customer or session. This proactive monitoring ensures a high-quality user experience and allows for rapid response to incidents before they impact a broad user base.
Overview
About Agenta
Agenta is an innovative open-source LLMOps platform that revolutionizes the way large language model (LLM) applications are developed and deployed. Designed to create a collaborative environment, Agenta enables developers and subject matter experts to work together seamlessly, experimenting with prompts, evaluating model performance, and debugging production issues efficiently. The platform addresses critical challenges faced by AI teams, such as unpredictable LLM behavior, fragmented prompt management, siloed communication, and an absence of structured validation processes. By centralizing the LLM development workflow, Agenta enhances team collaboration, improves workflow efficiency, and accelerates rapid iterations, ultimately leading to the creation of high-quality LLM applications. It serves as a single source of truth, ensuring that all team members—from product managers to developers and domain experts—can engage in a coherent and transparent process.
About Fallom
Fallom is an AI-native observability platform engineered to provide comprehensive, granular visibility into production large language model (LLM) and AI agent workloads. It serves as a critical operational layer for engineering, product, and compliance teams building and scaling AI-powered applications. The platform's core value proposition lies in its ability to monitor every LLM interaction in real-time with end-to-end tracing, capturing a complete telemetry dataset including prompts, outputs, tokens, latency, cost, and the intricate details of tool and function calls. This depth of insight is particularly vital for debugging complex, multi-step AI agents, where understanding the sequence and timing of operations is essential. Fallom is built for the enterprise, offering robust session, user, and customer-level context, alongside features like model versioning and consent tracking that address stringent compliance requirements such as the EU AI Act, GDPR, and SOC 2. By utilizing a single, OpenTelemetry-native SDK, Fallom ensures vendor-agnostic instrumentation, enabling rapid deployment, real-time monitoring, and precise cost attribution across models, teams, and end-users. Ultimately, Fallom transforms opaque AI operations into transparent, manageable, and optimizable systems, driving reliability, cost efficiency, and informed decision-making.
Frequently Asked Questions
Agenta FAQ
What is LLMOps, and how does Agenta fit into it?
LLMOps refers to the set of practices and tools designed to improve the development and deployment of large language models. Agenta fits into this framework by providing a centralized platform that streamlines collaboration, prompt management, evaluation, and observability.
Can Agenta integrate with existing tools and frameworks?
Yes, Agenta is designed to integrate seamlessly with a variety of existing tools and frameworks, including LangChain, LlamaIndex, OpenAI, and others. This flexibility allows teams to incorporate Agenta into their current workflows without significant disruption.
How does Agenta enhance team collaboration?
Agenta enhances team collaboration by providing a unified interface where product managers, developers, and domain experts can work together on prompt engineering and model evaluation. This reduces silos and improves communication across the team.
Is Agenta suitable for organizations of all sizes?
Absolutely. Agenta is designed to be scalable and adaptable, making it suitable for organizations of all sizes, from startups to large enterprises. Its open-source nature allows teams to customize the platform to fit their specific needs and workflows.
Fallom FAQ
What is OpenTelemetry, and why is Fallom built on it?
OpenTelemetry (OTEL) is a vendor-neutral, open-source standard for generating, collecting, and exporting telemetry data like traces, metrics, and logs. Fallom's native OTEL foundation means it uses a single, standardized SDK to instrument your application, ensuring you are not locked into a proprietary agent. This provides maximum flexibility, simplifies setup (often in under 5 minutes), and guarantees compatibility with a vast ecosystem of existing OTEL-compatible tools and backends for a future-proof observability strategy.
How does Fallom handle sensitive or private user data?
Fallom is designed with enterprise-grade privacy controls. Its configurable "Privacy Mode" allows administrators to disable full content capture for sensitive workflows. In this mode, the platform can be set to log only metadata (e.g., token counts, latency, model used) while redacting the actual prompts and completions. This enables teams to maintain full operational and cost observability while complying with data privacy policies and regulations like GDPR, ensuring user confidentiality is protected.
Can Fallom compare performance between different LLM models?
Yes, Fallom includes robust A/B testing and comparison features. Teams can split traffic between different models (e.g., GPT-4o and Claude-3.5) and use the platform to compare their performance in real-time across key dimensions such as cost per call, latency, token usage, and custom evaluation scores (e.g., accuracy). This data-driven approach allows for informed decisions when selecting or switching models, ensuring optimal balance between cost, speed, and quality for specific use cases.
Is Fallom suitable for small development teams or startups?
Absolutely. Fallom offers a free tier to start tracing, making it accessible for small teams and startups to instrument their AI applications quickly. The value of having immediate observability into LLM costs, performance, and errors is significant even at early stages, preventing technical debt and establishing best practices for scaling. The platform's simplicity and OpenTelemetry approach mean small teams can gain enterprise-grade insights without requiring dedicated observability personnel.
Alternatives
Agenta Alternatives
Agenta is an open-source LLMOps platform that centralizes prompt management, evaluation, and debugging for large language model applications. It is designed to enhance collaboration among developers and subject matter experts by providing a unified environment for experimentation and model performance evaluation. Users commonly seek alternatives to Agenta due to a variety of factors, including pricing, specific feature sets, or unique platform requirements that may not be fully addressed by Agenta. When considering alternatives, it is essential to evaluate the platform's ability to streamline workflows, enhance collaboration, and provide robust evaluation tools, ensuring that it meets the specific needs of your team and project. --- [{"question": "What is Agenta?", "answer": "Agenta is an open-source LLMOps platform that centralizes prompt management, evaluation, and debugging for large language model applications."},{"question": "Who is Agenta for?", "answer": "Agenta is designed for developers and subject matter experts working on large language model applications who need a collaborative environment for prompt experimentation and evaluation."},{"question": "Is Agenta free?", "answer": "Yes, Agenta is an open-source platform, which means it is available for free to users."},{"question": "What are the main features of Agenta?", "answer": "Agenta features centralized prompt management, a unified playground for experimentation, and an automated evaluation system to enhance the reliability of model modifications."}]
Fallom Alternatives
Fallom is an AI-native observability platform within the development and MLOps category, specifically designed to provide real-time monitoring, debugging, and cost analysis for large language model (LLM) and AI agent applications. It offers deep visibility into prompts, outputs, tool calls, and performance metrics, making it a specialized tool for teams deploying complex AI systems. Users may explore alternatives to Fallom for various reasons, including budget constraints, specific feature requirements not covered by the platform, or the need for integration with an existing tech stack or cloud provider. Some organizations might seek simpler solutions for basic logging or more extensive platforms that bundle observability with other MLOps functionalities like model training and deployment. When evaluating an alternative, key considerations should include the depth of LLM and agent-specific tracing, the ease of implementation and integration, robust cost attribution and analysis capabilities, and compliance features such as audit trails and consent management. The ideal platform should provide the necessary transparency and control without introducing excessive complexity or hindering development velocity.