WebPageSnap - Professional Web Scraper API
WebPageSnap is a powerful API for fast, reliable web scraping with global edge nodes and smart caching for optimal.
Visit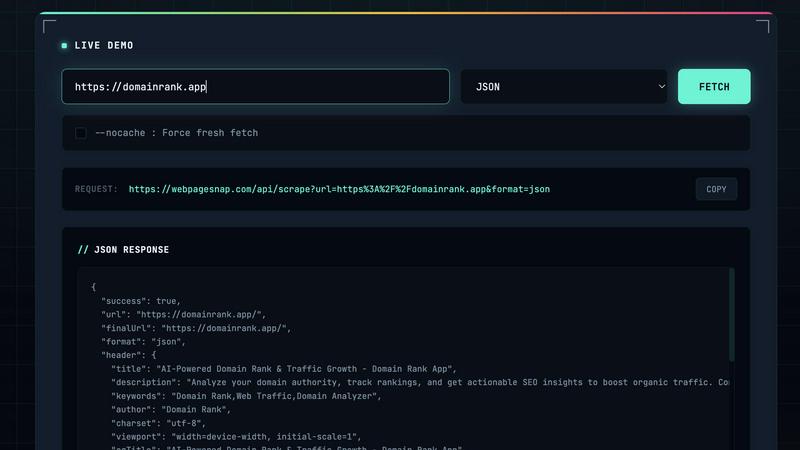
About WebPageSnap - Professional Web Scraper API
WebPageSnap is an enterprise-grade web scraping API designed for developers, data scientists, and businesses that need structured and reliable access to publicly available web content. The service excels in efficiently fetching, parsing, and caching data from web pages, converting any public URL into clean, structured JSON or raw HTML. Built on the robust infrastructure of Cloudflare Workers and supported by a global Content Delivery Network (CDN), WebPageSnap guarantees low-latency access for users worldwide. Its intelligent caching system, with a 7-day time-to-live (TTL) and a cache hit rate exceeding 95%, ensures that users receive quick responses, often in under 50 milliseconds. With features such as automatic following of JavaScript redirects and realistic browser simulation, WebPageSnap provides accurate data extraction from even the most complex websites. This API is ideal for organizations looking to leverage web scraping capabilities without the complexities of managing proxies, rate limits, or intricate parsing logic.
Features of WebPageSnap - Professional Web Scraper API
Smart Cache
The Smart Cache feature employs a key-value storage mechanism with a 7-day TTL and an impressive cache hit rate of over 95%. This optimizes the efficiency of data retrieval, allowing users to access frequently requested content swiftly and cost-effectively.
Global Edge
WebPageSnap is deployed on a network of over 200 edge nodes across the globe, ensuring that users receive fast responses by routing requests to the nearest server. This reduces latency significantly, making it ideal for applications that require real-time data access.
Multi Format
The API supports multiple output formats, allowing users to request either structured JSON data or raw HTML. This flexibility caters to diverse development needs, enabling seamless integration into various applications and workflows.
Smart Redirect
WebPageSnap intelligently follows JavaScript redirects, ensuring that users receive the final rendered content of web pages, even those heavily reliant on dynamic JavaScript. This capability is crucial for accurately scraping modern websites that employ advanced loading techniques.
Use Cases of WebPageSnap - Professional Web Scraper API
Content Aggregation
Businesses can use WebPageSnap to aggregate content from various sources, such as news articles or product listings, allowing for comprehensive market analysis and competitive intelligence. This capability enables organizations to stay informed and adapt strategies accordingly.
SEO Research
WebPageSnap is invaluable for SEO professionals looking to analyze website metadata. By extracting titles, descriptions, and Open Graph tags, users can optimize their own websites and improve search engine rankings based on competitor insights.
Data Analysis
Data scientists can leverage WebPageSnap to collect large datasets from multiple web sources, enabling them to perform in-depth analyses or machine learning tasks. This functionality allows for the extraction of real-time data that can enhance research and development efforts.
Market Monitoring
Organizations can utilize the API to monitor changes in competitor websites, such as pricing adjustments or new product launches. This real-time monitoring helps businesses remain competitive and responsive to market dynamics.
Frequently Asked Questions
What is a web scraper API?
A web scraper API is a service that automates the extraction of content from websites. WebPageSnap provides a structured approach to data extraction, offering output in both JSON and HTML formats for easy integration into applications and workflows.
How does WebPageSnap handle JavaScript-heavy pages?
WebPageSnap automatically detects and follows JavaScript redirects. Its realistic browser simulation ensures that users receive the final content of web pages, making it effective for scraping modern sites that utilize complex JavaScript for content loading.
Is there a limit to the number of requests I can make?
Yes, WebPageSnap offers a generous free tier allowing up to 1000 requests per day. This enables users to explore the API's capabilities without incurring costs while providing ample room for development and testing.
How can I integrate WebPageSnap into my application?
Integration is straightforward. Users can make API calls using standard HTTP requests, passing the target URL and desired format as parameters. Detailed documentation is available to assist developers in implementing the API seamlessly into their projects.
Explore more in this category:
Similar to WebPageSnap - Professional Web Scraper API
Sorsa API delivers fast and reliable X Twitter data at 50 times lower cost, with 20 requests per second and setup in just 3 minutes.
TrafficClaw transforms your SEO and analytics data into actionable insights through natural language conversations for effortless growth.
LinkFinder AI enriches your data with instant access to complete company details, enhancing your lead generation.
BlitzAPI provides clean B2B data APIs to power and automate scalable go-to-market strategies.
LLMWise offers a single API to seamlessly access and compare top AI models like GPT, Claude, and Gemini with.
AntiTemp is an email intelligence API that verifies authenticity, aligning Product, Growth, and Risk teams with.
My Deepseek API offers affordable and scalable AI solutions with reliable performance for all your data needs.
CCAPI is a unified multimodal AI API gateway providing seamless access to various AI models for text, image, audio, and.